Local Dimension Enhancement Representation Learning for Skeleton-Based Action Segmentation
Abstract
Most existing self-supervised learning methods for skeleton-based temporal action segmentation (TAS) fail to capture the short-term motion semantics essential for dense frame-level prediction, as they typically learn representations that are either too coarse or motion-insensitive. This issue is reflected in local dimension collapse, which highlights the limitations of current approaches and suggests directions for improvement. Specifically, to address the issue of local dimension collapse for self-supervised learning in TAS, we propose the Local Dimension Enhancement (LoDE) framework, which introduces the local effective rank (LER) as a metric to measure and a learning objective to reduce this collapse. A new fine-grained representation scale, termed a motion unit, is defined as a temporal clip of consecutive skeleton frames to model skeleton data. Centered on this representation scale, we analyze existing methods (sequence-scale and frame-scale learning) with the tool of LER and theoretically demonstrate that introducing motion unit-scale learning is essential to alleviate local dimension collapse. Inspired by our theoretical insights, we design a multi-scale semantics module that integrates frame-, sequence-, and motion unit-scale learning, with LER-based regularization to enrich local representation diversity. These designs effectively alleviate local dimension collapse and lead to significant improvements in TAS, as evidenced by LoDE's superior performance over state-of-the-art methods on three large-scale untrimmed datasets: PKUMMD, TSU, and BABEL.
Framework
Our Local Dimension Enhancement (LoDE) framework. (a) LoDE learns motion unit-scale representations by applying a masked modeling strategy with weight-sharing Siamese encoders. (b) The Multi-scale Action Semantics Learning (MASL) module captures multi-scale semantics by aligning the reconstructed objectives from the masked view with original skeletons and quantized representations from the unmasked view. (c) LER regularization (LERR) is applied to the masked view to encourage a more uniform singular value distribution and increase local intrinsic dimension.
Core Theoretical Insights
1. Quantifying Local Dimension Collapse
We introduce Local Effective Rank (LER) to measure the dimensionality of the latent space within local regions. Based on the singular values \( \sigma_i \) of the local representation matrix, LER is defined as:
As stated in Proposition 1, LER is a tight upper bound for the matrix rank: \( 1 \leq \text{LER}(Z) \leq \text{rank}(Z) \), providing a stable indicator of representation diversity.
Empirically, our analysis confirms that a higher LER corresponds to a larger minimal achievable rank (preserving more information), and exhibits a strong positive correlation indicated by high Pearson correlation coefficient (PCC) value with downstream temporal action segmentation (TAS) performance evaluated by mean average precision (mAP).
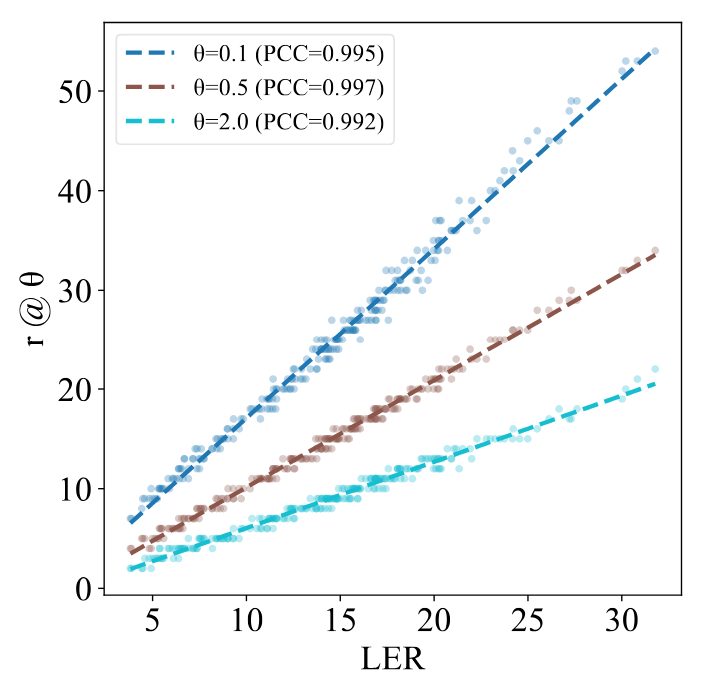
(a) LER vs. minimal achievable rank r.
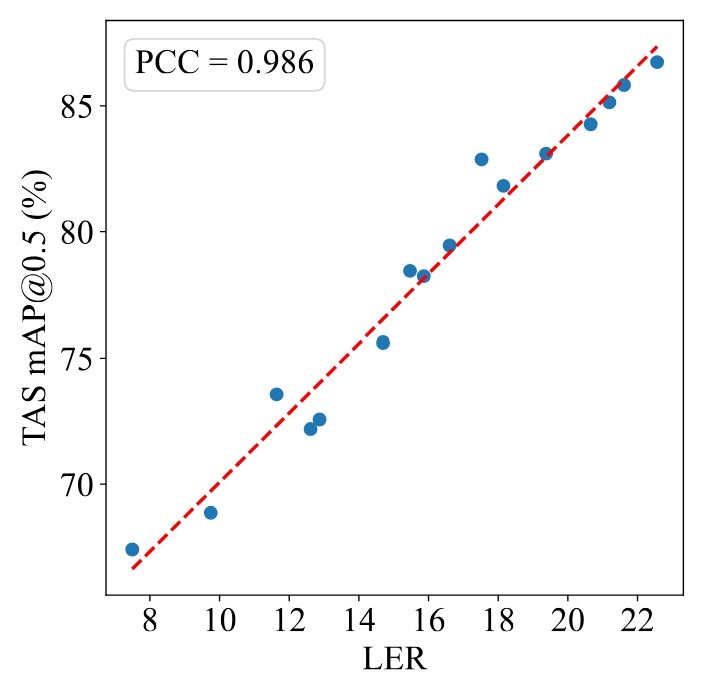
(b) LER vs. downstream TAS performance (PCC=0.986).
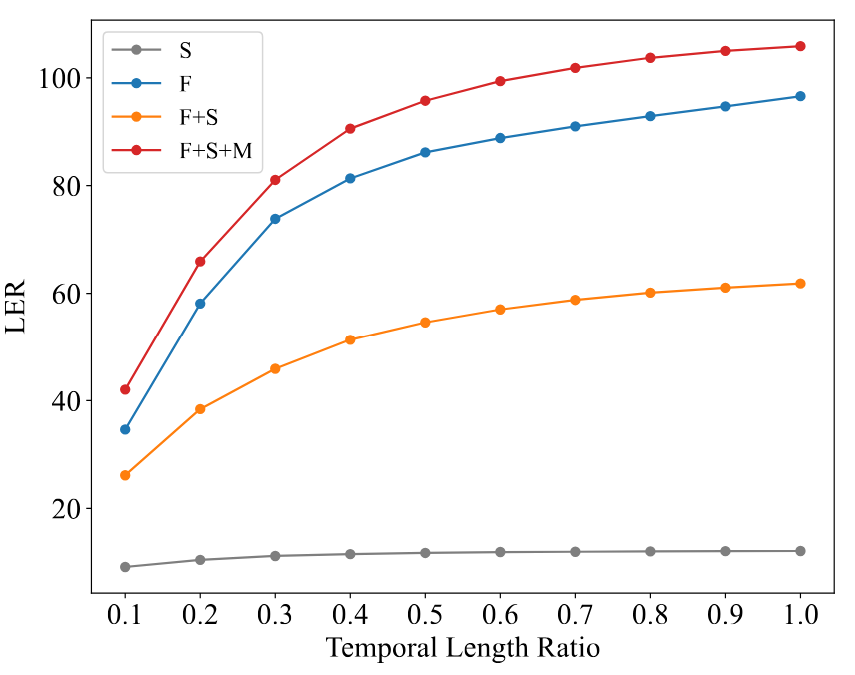
Comparison of LER across different modeling scales. F, S, and M denote models trained with frame-, sequence- and motion unit-scale objectives, respectively.
2. Why Motion Unit Scale?
With the tool of LER, we reveal the theoretical limitations of existing modeling paradigms: sequence-scale learning heavily suffers from local dimension collapse by indiscriminately pulling local representations together, while frame-scale learning is inherently bounded by the low dimensionality of raw skeletons.
Our Proposition 4 reveals that the lower bound of LER is inversely proportional to the squared Frobenius norm of the similarity matrix of local representations \( Z \):
By introducing Motion Units (clips of consecutive frames), we enrich local short-term semantics, effectively minimizing \( \|Z^\top Z\|_F^2 \) and increasing the lower bound of LER to alleviate local dimension collapse.
Experimental Results
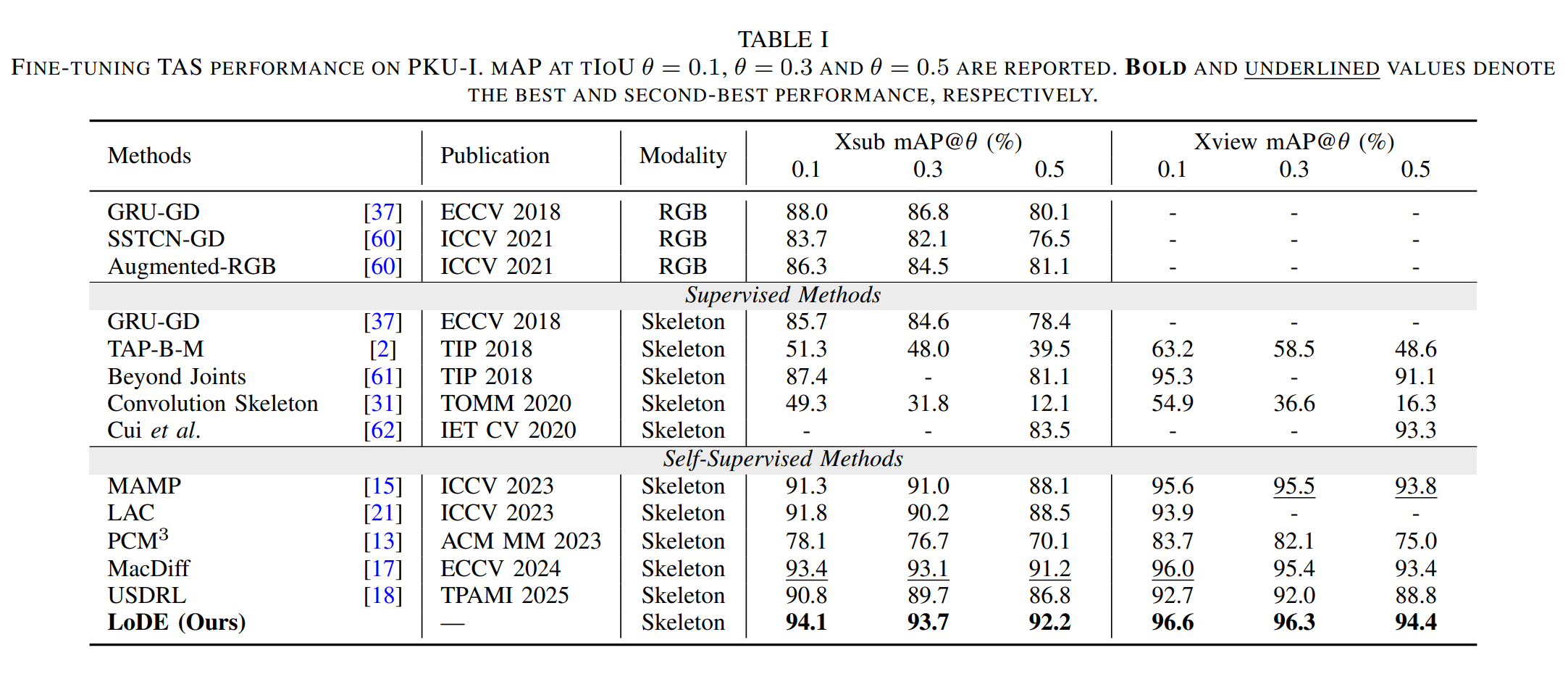
Remark 1: Fine-tuning temporal action segmentation performance on PKU-I. It demonstrates the superior TAS performance achieved with the learned high-quality representations.
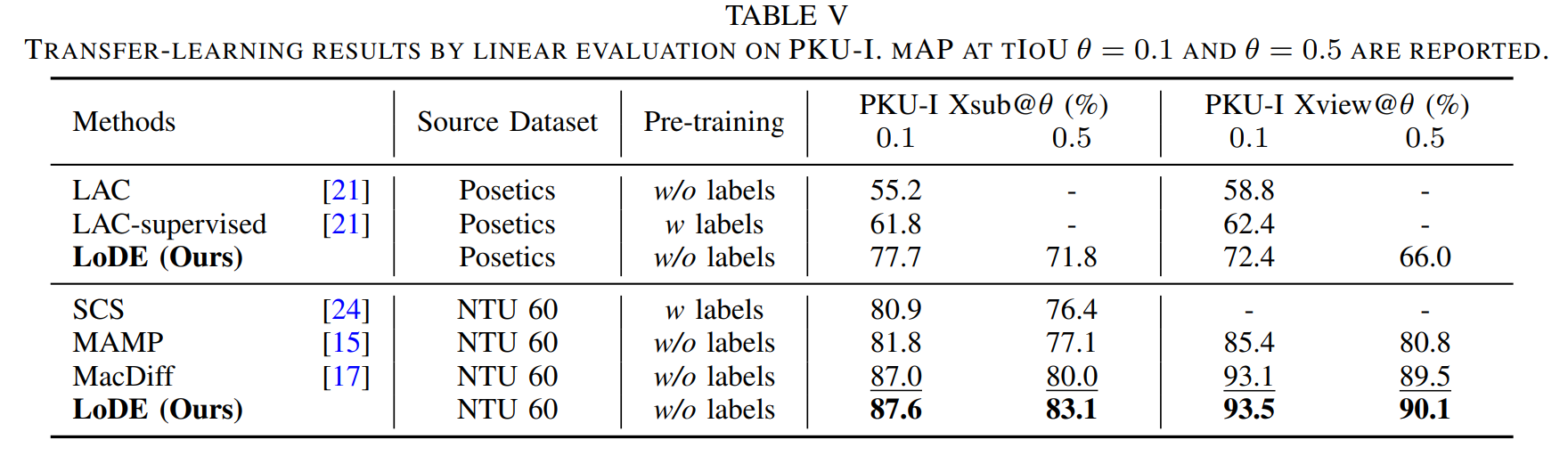
Remark 2: Linear evaluation of temporal action segmentation performance with transfer learning protocol. The results shows the great generalizability of the learned representations across different input distributions.
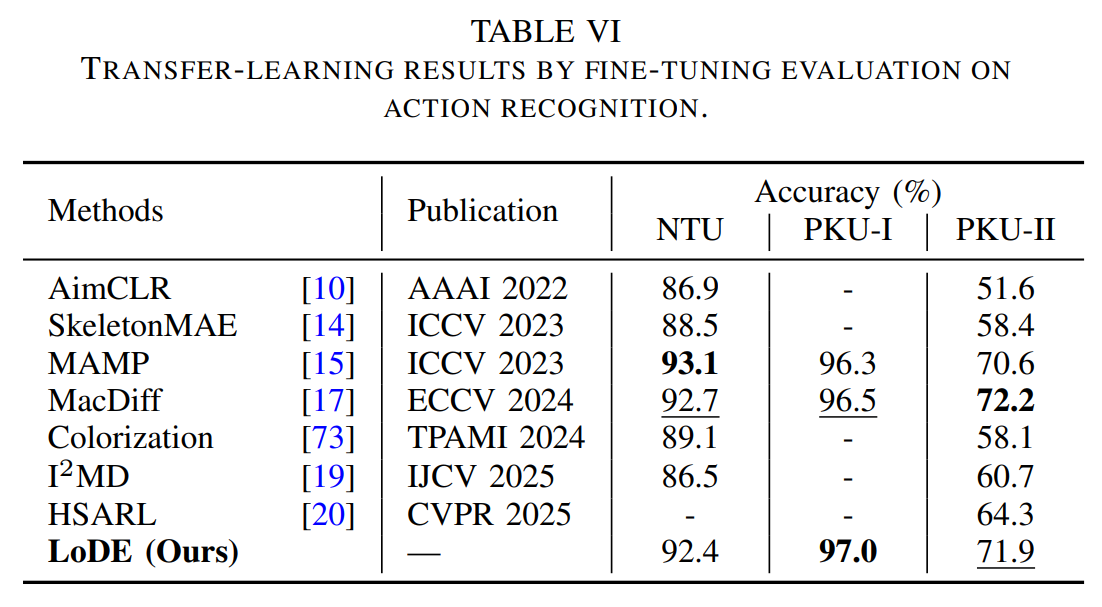
Remark 3: Fine-tuning action recognition performance. It demonstrates the compatibility of our method with action recognition, verifying the generalizability of the representations across action understanding tasks of different granularities.
BibTeX
@ARTICLE{11481594,
author={Sun, Shaofan and Lin, Lilang and Zhang, Jiahang and Duan, Ling-Yu and Liu, Jiaying},
journal={IEEE Transactions on Image Processing},
title={Local Dimension Enhancement Representation Learning for Skeleton-Based Action Segmentation},
year={2026},
volume={35},
number={},
pages={3970-3983}}
References
If you have any questions, please contact Shaofan Sun (carefree_sun@stu.pku.edu.cn).